Project Background
This blog details the preparation and implementation process of a web crawler project. The goal of this project is to get image links from Bing image search and download images. Such crawler projects are usually used to collect a large amount of image data for training various artificial intelligence models, especially computer vision models. Research in the field of computer vision requires a large amount of image data to train and test models in order to achieve functions such as image classification, object detection, and image generation.
1. Project Preparation
Environment Configuration
Before you start writing a crawler, make sure you have completed the following environment configuration:
Python installation: Make sure that Python 3.x version is installed. Python is a powerful and easy-to-learn programming language suitable for a variety of programming tasks, including web crawler development.
Required libraries: Python has a large ecosystem of third-party libraries, and we will use several core libraries to develop crawlers:
-
requests: used to send HTTP requests and process responses.
-
os: provides functions for interacting with the operating system for file operations such as creating folders.
-
time: provides time-related functions, such as sleep programs and timing.
-
urllib: provides some functions for getting data on the network, mainly for URL encoding.
You can use the following command to install these libraries through pip:
pip install requests
If you are using an integrated environment such as Anaconda, you can use the conda command:
conda install requests
These libraries will help us process HTTP requests, parse and store data, and perform some basic system operations.
2. Crawler Design and Implementation
Crawler Design Ideas
Target Website Analysis
Before designing a crawler, it is essential to analyze the target website. For the Bing image search website, we conducted the following analysis:
-
Webpage structure: The results of the Bing image search page are usually presented in HTML, which contains thumbnails of multiple images. The thumbnail of each image is usually displayed through the <img> tag, and the real link of the image is saved in the src attribute.
-
Dynamic loading: Bing's image search results may use dynamic loading. That is, when the page is initially loaded, only some images may be loaded, and more images will be loaded dynamically when the user scrolls the page. Selenium can simulate user behavior (such as scrolling) to load these dynamic contents.
-
Request restrictions: Bing image search may limit request frequency or IP address. Using a proxy server helps to spread the request load and avoid IP blocking.
Data acquisition process
-
Build the request URL: Build the URL of Bing image search based on the search keywords entered by the user. The format of the URL is usually https://www.bing.com/images/search?q={search term}, where {search term} is the user's query content.
-
Send GET request: Send a GET request through Selenium WebDriver to load the target web page. Since the Bing image search page may contain dynamic content, Selenium can handle these dynamically loaded contents to ensure that the image link is fully loaded.
-
Parse web page data: Use Selenium to parse the web page source code and extract the src attribute of all image thumbnails. Usually, thumbnail links can be found through CSS selectors, such as using the img.mimg selector to obtain image tags.
-
Download images: For each extracted image link, use the Requests library to send a GET request to obtain the image data and save it to a local directory. Make sure to handle any possible download exceptions when saving, such as network problems or invalid links.
Storage management: Save the downloaded images to a pre-created directory. The directory structure can be classified by search terms for easy subsequent management and use.
Code Implementation
The following are the main parts of the code and their functional descriptions:
1. Initialize the crawler class (BingImageSpider)
In the crawler development process, you first need to define a crawler class to implement the image crawling function. We define a class called BingImageSpider to handle the task of crawling and downloading images from the Bing image search page.
import requests
import os
import time
from urllib import parse
class BingImageSpider(object):
def __init__(self):
self.url = 'https://www.bing.com/images/search?q={}&form=HDRSC2&first=1&tsc=ImageBasicHover'
self.directory = r"D:SDpython-mini-projectsprojectsingimg{}"
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept-Language': 'en-US,en;q=0.9',
'Referer': 'https://www.bing.com'
}
2. Create a storage folder
In the process of image crawling, in order to organize and manage the downloaded images, you need to create a special storage folder. The name of this folder is usually related to the search keyword to facilitate subsequent search and management. The following is the code to create a storage folder for images:
def create_directory(self, name):
self.directory = self.directory.format(name)
if not os.path.exists(self.directory):
os.makedirs(self.directory)
3. Get image link
This method obtains web page content by sending an HTTP request and obtains the thumbnail link of the image from the Bing image search results page:
def get_image_link(self, url):
list_image_link = []
response = requests.get(url, headers=self.header)
# Parse web page content and extract image links
try:
json_data = response.json()
for item in json_data['value']:
if 'thumbnailUrl' in item:
list_image_link.append(item['thumbnailUrl'])
except Exception as e:
print(f"Error occurred: {e}")
return list_image_link
Returns a list of all extracted image thumbnail links for subsequent image download operations.
4. Download images
The main task of this code is to download the specified image and save it to local storage. To implement this function, you need to handle network requests, file operations, and error handling. Below is the implementation code of this method:
def save_image(self, img_link, filename):
try:
res = requests.get(img_link, headers=self.header)
with open(filename, "wb") as f:
f.write(res.content)
print("path:" + filename)
except requests.RequestException as e:
print(f"Error downloading image: {e}")
-
Download image: This method accepts two parameters: img_link and filename. img_link is the URL link of the image to be downloaded, and filename is the local file path where the image is saved. The method downloads the image data through HTTP request and writes it to the specified file.
-
File storage: The downloaded image is written to the local file system in binary mode ("wb") to ensure that the image data is correctly saved.
This method can ensure that the images downloaded from the network are correctly stored locally for subsequent use and management.
5. Use Proxy302 proxy IP
In web crawlers, frequent requests may be identified as abnormal traffic by the target website, resulting in the IP address being blocked. To reduce this risk, you can use proxy IP services such as Proxy302. Proxy302 and 302.AI are from the same development team. 302.AI is an AI supermarket that brings together top global brands. It is pay-as-you-go, has no monthly fee, and is fully open to all types of AI. The account balance of Proxy302 and 302.AI is universal.
First, we go to the proxy302.com official website to register an account and select the proxy ip we need.
Define a variable proxy, which contains the address and port number of the proxy server you want to use. In this example, the address of the proxy server is proxy.proxy302.com and the port number is 2222.
# Configuring the Proxy proxy = "proxy.proxy302.com:2222" # Proxy Address:Port
Create an Options object, which is a configuration class provided by Selenium for setting various options of the Chrome browser.
chrome_options = Options()
chrome_options.add_argument(f'--proxy-server=http://{proxy}')
-
Add a new command line parameter to the startup options of the Chrome browser through the add_argument method. This line of code adds the --proxy-server parameter to specify the proxy server to be used.
-
http://{proxy} means connecting to the proxy server using the http protocol, and {proxy} is the proxy address and port defined above. Ultimately, this parameter tells the Chrome browser that all network requests must be made through this specified proxy server.
Reliability and flexibility are crucial considerations when choosing a proxy service. Proxy302 has become the first choice for many users with its comprehensive proxy types, diverse supported protocols, and flexible pricing models. These advantages not only ensure efficient data collection, but also provide great convenience for applications in different scenarios.
The most comprehensive proxy types: Proxy302 provides the most comprehensive proxy types on the market to meet various business needs.
-
240+ countries and regions around the world, 65 million residential IPs to choose from.
-
Proxy302 supports HTTP and SOCKS5 network protocol proxies.
-
Proxy302 supports dynamic and static proxies. The proxy types are divided into [dynamic charge by traffic], [dynamic charge by IP], [static charge by traffic], and [static charge by IP]. Static proxies are also divided into residential IP and data center IP.
Simple and easy to use: The user interface is simple but not simple, easy to use and efficient. Provide browser extension plug-ins to achieve one-click proxy settings, eliminating complex configuration steps.
Pay as you go, no monthly payment package: No package bundle purchase is required, pay as you go, recharge to use all types of proxy IPs, no tiered pricing.
Use proxy IP This method can effectively hide the real IP address, thereby avoiding the risk of being blocked.
6. Main run function
The run function is the entry point of the program, responsible for controlling the execution process of the entire crawler. It processes user input, builds the request URL, extracts the image link, downloads the image, and performs appropriate delays to prevent too frequent requests. The following is the specific code of the run function:
def run(self):
searchName = input("Query content:")
self.create_directory(searchName)
search_url = self.url.format(parse.quote(searchName))
image_links = self.get_image_link(search_url)
for index, link in enumerate(image_links):
self.save_image(link, os.path.join(self.directory, f"{index + 1}.jpg"))
time.sleep(1) # Preventing too frequent requests
Through these methods, crawlers can efficiently obtain and download relevant images from Bing image search and realize automated image data collection.
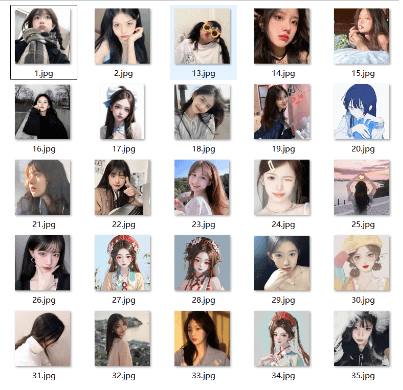
3. Summary
This document introduces how to implement a simple Bing image crawler using Python, and explains the functions and logic of each part of the code. At the same time, in order to avoid the risk of IP blocking caused by frequent requests, we also introduce how to use the Proxy302 proxy IP service in the crawler. Through this project, you can easily obtain a large amount of image data for training computer vision models or other purposes.