Duplicate content issues affect 99% of websites, but many are unaware of their existence. This article serves as a checklist to help diagnose and resolve excessive duplicate content pages, marking an important milestone in your SEO optimization journey.
When starting SEO optimization, most websites focus on addressing internal technical issues, and among them, resolving "duplicate content" is both crucial and common. It’s no exaggeration to say that nearly every website encounters duplicate content problems, but many people fail to recognize them. This checklist aims to assist in identifying and solving these issues, a key step in improving SEO performance.
Consequences of Duplicate Content
What exactly is duplicate content? Duplicate content refers to substantial portions of content that are either identical or very similar across the same domain or across different domains. In most cases, its cause is not deceptive in nature, so it won’t necessarily lead to penalties.
Only in rare situations, when Google believes that duplicate content is being used to manipulate rankings or deceive users, will the search engine take action, adjusting indexing and rankings accordingly.
Having a large amount of duplicate content can negatively impact a website:
-
Wasting Crawling Quota: As previously mentioned, search engine crawlers have a limited amount of time to spend on crawling a website. Duplicate pages will take up this quota, which may result in important pages not being crawled.
-
Reducing SERP Visibility: When a search engine identifies duplicate content, it filters out redundant pages to offer a more diverse set of search results, preventing some of your pages from ranking well.
-
Diluting Page Authority: If the same content is accessible through multiple URLs, search engines will divide the authority between these pages, which hinders their ability to rank effectively.
Types of Duplicate Content
Whether your website is a simple CMS template with a small number of pages or a complex site with millions of pages targeting multiple markets, duplicate content issues tend to fall into similar categories. Below are some common causes of duplicate content that you may encounter:
1. Caused by Internal Technical Issues
Technical issues within the website often lead to duplicate content. One of the most common problems is having multiple different URLs displaying the same content.
Common Duplicate Content Types:
-
Multiple Homepage URLs: The homepage is accessible via several URLs such as
/,index.html, andindex.php. -
Case-Sensitive URLs: For search engines, URLs that differ in capitalization are treated as separate pages (e.g.,
/pageand/Page). -
Inconsistent Use of Trailing Slashes: URLs with and without trailing slashes are treated as different pages (e.g.,
example.com/pagevs.example.com/page/). -
Flash and Iframe Content: Pages with Flash or iframe content that cannot be crawled by search engines will result in empty pages, which are considered duplicates.
-
Dynamic Filtering in Navigation: When various filter options, sorting, and parameters in multi-dimensional navigation are visible to search engine crawlers, each filtered combination generates a new page. If these filters are applied indefinitely, the crawler could follow these paths endlessly, resulting in the creation of an overwhelming number of pages. This issue can trap crawlers in a loop, as seen in a case where CrossBorderDigital helped a client resolve this problem, leading to a 30% SEO traffic boost.
-
Tracking Parameters in Internal Links: URLs containing tracking parameters, such as UTM tags from Google Analytics, can create duplicate pages.
-
Crawlable Dynamic Search Links: Dynamic search result pages, such as
/search?keywords=XXX, can be indexed by search engines. -
Print-Friendly Versions: Pages with print-friendly versions that are indexed as duplicates.
By recognizing and addressing these internal technical issues, you can effectively mitigate the negative impact of duplicate content on your SEO performance. The next step involves implementing solutions tailored to each specific type of duplicate content.
Caused by Inappropriate Content Strategy
In addition to technical issues, poor content strategy can also lead to duplicate content problems. In today's information-heavy era, content production and expiration happen rapidly, causing new challenges.
For large news websites with millions of pages and high content output, the issue of duplicate content and internal competition can become overwhelming.
Types of Duplicate Content
-
Publishing many similar articles or content updates where the duplication rate between articles is high.
-
Outdated content that has been replaced by newer content but hasn't been merged, resulting in the retention of old articles.
-
Pages with thin or blank content (such as pages that return a 200 status code but display a "404 Not Found" message). These pages are often reported as "Soft 404" errors in Google Search Console and are also classified as duplicate content.
FAQ: Handling Duplicate Content from External Sources
Q: What should I do if other websites copy our content, resulting in passive duplicate content?
A: Google's algorithm is quite capable of recognizing the original content. So, ranking should not be a concern. You can contact the webmaster of the offending site and request the removal of the copied content. Alternatively, you can file a Digital Millennium Copyright Act (DMCA) request to have Google remove the infringing web pages from search results.
For retail and e-commerce websites that are primarily product-focused, with fewer blog posts, duplicate content still requires attention.
Types of Duplicate Content
-
Repetitive customer reviews across different product pages.
-
Highly templated product category pages with little customization and high duplication rates. For example:

-
Empty category pages: Due to product adjustments, some categories no longer have products, but there are still links on the site leading to these blank pages.
-
Excessive use of duplicated content on paginated pages. One of the most common cases is the repetition of the same description across different pagination levels of a product category.
-
Repeated use of template text: Hundreds or thousands of product pages on e-commerce websites often display identical information such as shipping and return policies.
-
Product descriptions that are identical to those displayed on third-party platforms like eBay and Amazon.
-
Using original supplier-provided materials without customizing or modifying them for the website.
-
Duplicate Title tags and Meta Descriptions across multiple pages. For example, some B2B websites pile the same product keywords into every page.
-
Multiple URLs leading to the same product page, generated through different product categories or promotional dimensions.
By addressing these content strategy pitfalls, you can avoid common SEO issues related to duplicate content and ensure your website’s overall health and ranking.
Caused by Server Configuration Issues
When errors occur in server configuration, there is a high chance of duplicate content issues, yet most website operators struggle to notice these problems.
Types of Duplicate Content
-
After implementing an SSL certificate, the HTTP links do not redirect to the secure protocol HTTPS, effectively doubling the number of website pages as seen by search engines.
-
Both www and non-www versions of the site exist without proper redirection.
-
Load balancing configured on backup subdomains (such as www3.) or load balancing at the IP level.
-
Test site pages are indexed, resulting in duplicate content between the test environment and the live website.
Caused by Internationalization/Multidomain Websites
If your website targets international markets, you may be operating different country-level domains or subdomains. In this case, it’s essential to inform Google about the localized versions of your web pages.
Types of Duplicate Content
-
Publishing the same or highly similar content on domains aimed at different markets.
-
A multilingual site that hasn’t correctly deployed the
<hreflang="lang">tag, or hasn’t translated the content into the local language. If the primary content of the page hasn’t been translated, the localized version will be treated as a duplicate page. -
Separate mobile sites (such as a subdomain m.crossborderdigital.com) and PC sites that lack proper canonical and alternate annotations in both directions.
How to Diagnose?
Using search engine query commands or relevant checking tools to accurately identify the root causes is key to effective SEO. To help you quickly diagnose issues on your site, here are three methods:
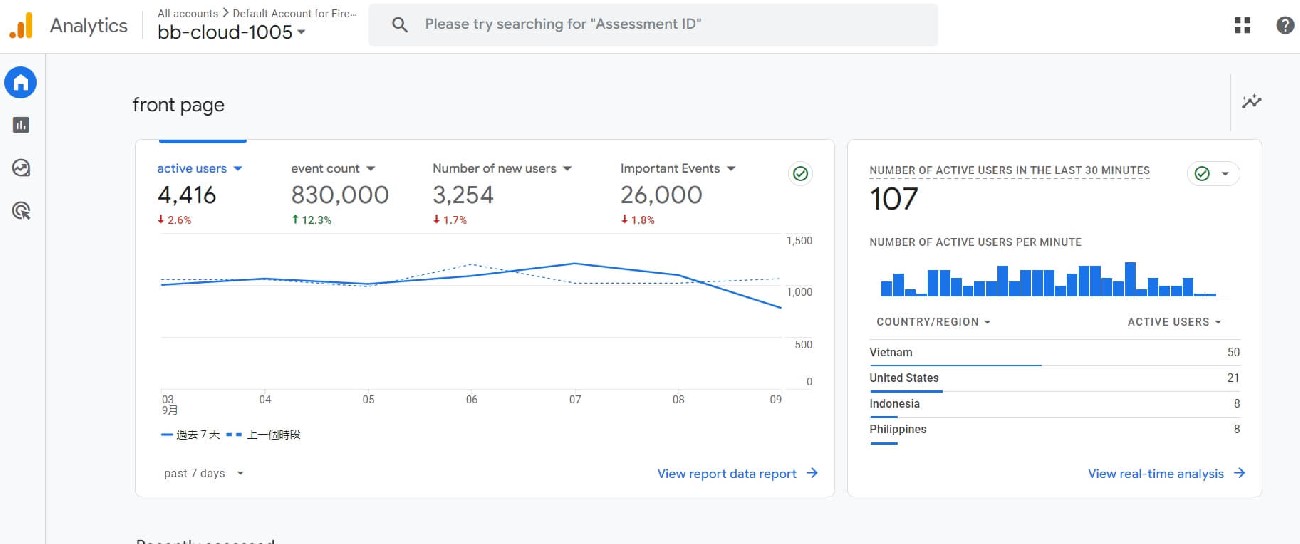
Google Search Console Index Report
The most straightforward way is to check the "Coverage" report in the Google Search Console. This report provides a list of error links or those excluded from indexing. It clearly shows why certain pages on your website are not being indexed. As shown in the image below:

Search Engine Query Commands
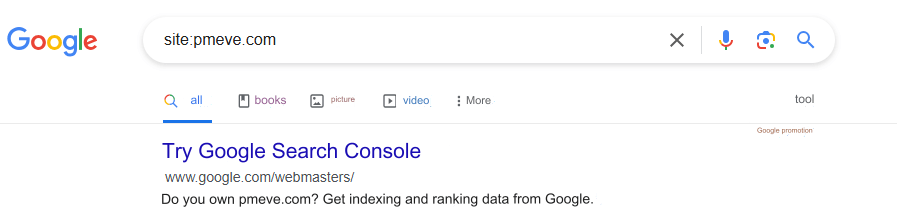
Another simple method for finding duplicate content is by using Google query commands. Simply copy a portion of text content from your website, enclose it in quotation marks, and search it on Google.
To check how many pages from your website have been indexed, aside from viewing the number of Valid URLs in Google Search Console, you can also use the command site:www.example.com to get an estimated count of indexed pages. (This is a reference value depending on the size of the site.)

For quicker and more efficient detection of duplicate content, combine the following search commands:
Useful Google Search Commands:
✅ site:www.example.com
This command checks the number of indexed pages on the website.
✅ site:www.example.com intitle:keyword
This command lists all pages on your website with "keyword" in the title.
✅ site:www.example.com inurl:keyword
This command lists all URLs on your website that contain "keyword."
✅site:www.example.com filetype:xml/txt/pdf
This command finds pages on your website that contain specific file types like XML, TXT, or PDF.
Web Crawling Tools
With growing demand comes a growing market—there are more tools than ever to detect duplicate content, each with increasingly sophisticated features. The most important thing is to find a tool that works for your needs.
One highly recommended tool is Screaming Frog, a popular crawler simulation tool that can help you quickly detect duplicate titles, descriptions, H tags, and URLs. It also allows you to export reports in bulk for easier analysis.
If you're already using similar tools like Deepcrawl and Sitebulb, or comprehensive SEO tools such as Ahrefs and SEMRush, they will also work effectively for this purpose.

How to Optimize
Once you have identified duplicate content and diagnosed the problematic pages, the next crucial step is optimizing and resolving these issues. This helps consolidate page authority, improves the efficiency of search engine crawlers, and increases the number of indexed pages.
Set Up 301 Redirects
For search engines, a 301 redirect signifies a permanent change of address and can pass the majority of a page’s authority and ranking.
If a page has multiple URL entrances, or if you're dealing with outdated content being replaced by new versions, it's advisable to choose a preferred, canonical URL and set up 301 redirects from other pages to this canonical version to consolidate page authority.
Add rel="canonical"
Every page on your website should include a rel="canonical" link element. This helps Google select one URL as the canonical version and treat all other URLs as duplicates, reducing the crawl frequency for these duplicate URLs and consolidating page authority.
While the canonical tag doesn’t pass all the authority like a 301 redirect, it still consolidates most of the authority to the preferred page, as long as the two pages are identical or highly similar. If you want to retain access to all existing URLs but can’t easily set up 301 redirects, using the canonical tag is a good compromise.
Canonical Tag Considerations:
-
The canonical tag is a suggestion, not a directive. While search engines will consider the tag, they may not always follow it, taking other factors into account to determine the canonical URL.
-
The tag must use absolute URLs, meaning the URL should include the
httporhttpsprotocol. -
The content of the canonical page should be identical or very similar to the non-canonical URLs. Otherwise, the tag may not work effectively. Unlike 301 redirects, canonical tags require careful verification to ensure content consistency.
Add Noindex Tags
If 301 redirects and canonical tags aren’t feasible, and you want to prevent search engines from indexing certain duplicate pages, you can add a Noindex tag to the page’s source code. This prevents the page from being indexed but still allows crawlers to follow links on the page and pass authority. For example:
<meta name="robots" content="noindex,follow">
While robots.txt blocks crawling (but not indexing), Noindex blocks indexing (but not crawling). These are two separate processes, but inexperienced users may opt to use robots.txt to block duplicate pages, which doesn’t solve the issue at its core. It's better to use the Noindex tag and, after confirming the page is removed from Google's index, add it to the robots.txt file to block crawling.
For example, for missing content pages or internal search pages that you don't want indexed, use the Noindex tag first, and then block them from being crawled with robots.txt once they are de-indexed.
Ensure Internal Links Are Canonicalized
All internal links should point to the canonicalized URLs to improve crawler efficiency and reduce entry points for duplicate pages. For instance, ensure that the homepage navigation's "Home" link, website logo, and breadcrumb navigation all point to the preferred URL.
Minimize Template Content
For example, on e-commerce websites, avoid displaying duplicate information such as shipping or warranty terms on every product page. Instead, use anchor text to link to a dedicated page with detailed information. Additionally, minimize similar content across the site. If you regularly publish version update documents, try to add unique content for each new version or consolidate the versions into a single page.
Commit to Original Content
If your company operates across multiple platforms (e.g., products sold on eBay, Amazon, and your website), prioritize creating original content for your website. Ensure that product and category descriptions are customized and highly readable to boost long-term competitiveness. If you source products from suppliers, take extra steps to optimize the product descriptions provided to avoid duplicate content with other websites.
Note: If your website has too many product SKUs, updating all the content can be a lengthy process. It’s recommended to start with the high-traffic pages, using tools like Google Analytics to identify the most important pages.
Keep URLs Stable
If possible, avoid changing URLs frequently, as URL stability is more important than constantly adding new keywords. Over time, changing URLs can lead to 404 errors or create other duplicate content issues.
Prevent Unconditional Content Usage
If you run a content-heavy site with many high-quality documents, it’s possible that competitors or other platforms may scrape or cite your content. In such cases, set up your website to automatically add copyright information and a link to the original page whenever someone copies your content. This ensures your content's originality remains intact.