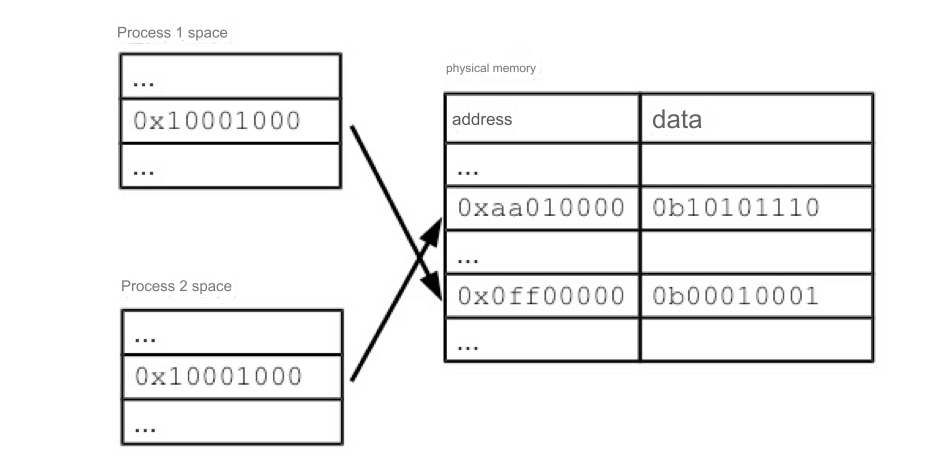
This article aims to explore some challenges in programming through the lens of Rust's language design, particularly its important programming paradigms, as this approach may offer deeper insights.
The article is quite lengthy and contains a lot of code, so it's essential to have the following knowledge before reading:
You should be familiar with certain features and issues of C++, especially pointers, references, rvalue moves, memory object management, generic programming, and smart pointers. While a basic understanding of Rust is helpful, this article is not a tutorial; you may refer to the "Official Rust Tutorial" for that.
Due to the length of this article, a TL;DR is necessary:
Java and Rust have taken entirely different paths in improving C/C++, focusing mainly on addressing C/C++ safety issues. The safety concerns in C/C++ programming primarily revolve around memory management, and problems like dangling pointers and references that arise from data sharing.
To tackle these issues, Java employs reference garbage collection combined with powerful VM bytecode technology, allowing for various "black magic" techniques like reflection and bytecode modification. In contrast, Rust does not use garbage collection or VMs, so it relies on the compiler for safety. To enable the compiler to detect safety issues at compile time, programmers must adhere to certain conventions in Rust, with ownership being a primary rule. Additionally, programmers are required to clarify the lifetimes of shared references in their code.
These ownership conventions in Rust can create significant programming challenges; essentially, you should not expect your Rust code to compile easily. Writing code for certain scenarios, such as functional closures, shared immutable data in multithreading, and polymorphism, becomes more complex and can leave you feeling lost.
Rust's traits are similar to Java's interfaces, enabling operations like copy construction, operator overloading, and polymorphism, akin to C++. The learning curve for Rust is steep, but once code compiles, it is generally safe and has fewer bugs.
If your understanding of Rust's concepts is incomplete, you may struggle to write even simple programs. This requirement forces programmers to grasp all concepts before coding, which also implies that Rust may not be suitable for beginners.
Variable Mutability
In Rust, variables are immutable by default. For instance, declaring a variable as let x = 5; makes x immutable; attempting to reassign it (e.g., x = y + 10;) will result in a compiler error. To declare a mutable variable, you need to use the mut keyword, such as let mut x = 5;. This approach is interesting because most mainstream languages allow mutable variables by default, while Rust opts for immutability. Immutability typically offers better stability, while mutability can lead to instability. Hence, Rust aims to be a safer language by defaulting to immutable variables. Rust also has constants declared with const.
Here are some examples:
Constant:
const LEN: u32 = 1024;whereLENis a constant of typeu32(unsigned 32-bit integer), evaluated at compile time.Mutable Variable:
let mut x = 5;similar to other languages, used at runtime.Immutable Variable:
let x = 5;You cannot modify this variable, but you can redefine it aslet x = x + 10;, a practice called shadowing in Rust, where the secondxobscures the first.
Immutable variables contribute to stable program execution, creating a programming "contract" that enhances stability, particularly in multithreaded environments, since immutability implies read-only access. Additionally, immutability makes objects easier to understand and reason about, providing higher safety. This "contract" enables the compiler to check for many programming issues at compile time.
In C/C++, we use const to denote immutability, while Java uses final, C# employs readonly, and Scala uses val. In dynamic languages like JavaScript and Python, primitive types are generally immutable, while custom types can be mutable.
Regarding Rust's shadowing, I personally find it quite risky. In my career, bugs arising from using identically named variables in nested scopes have been difficult to trace. Generally, each variable should have a unique, appropriate name to avoid conflicts.
Ownership of Variables
This is a concept that Rust emphasizes significantly. In programming, we often pass objects (variables) back and forth, and the question arises: are we passing a copy of the object, or are we passing the object itself? This is the commonly asked question about “pass by value or pass by reference.”
Passing Copies (Pass by Value): When passing a copy of an object to a function or placing it in a data structure, a copy operation may occur. For safety, deep copying is often required for objects; otherwise, various issues can arise. However, deep copying can lead to performance problems.
Passing the Object Itself (Pass by Reference): Passing by reference avoids the cost of copying the object but introduces the problem of multiple variables referencing the same object. For example, if we pass a reference of an object to a List or another function, all references share control over the same object. If one reference releases the object, the others will be affected. Therefore, reference counting is typically used to manage shared objects. Additionally, there are scope issues; for instance, if you return a reference to an object from a function’s stack memory, the caller will receive a reference to a released object (since the stack is cleared after the function ends).
These challenges must be addressed in any programming language, requiring sufficient flexibility for programmers to write according to their needs.
In C++, if you want to pass an object, you have several options:
Reference or Pointer: This avoids creating a copy and allows complete sharing. However, it can lead to the issue of dangling pointers (wild pointers) where a pointer or reference points to deallocated memory. C++ addresses this problem using managed classes like
shared_ptrto manage reference counting during sharing.Pass by Copy: This involves passing a copy and requires overloading the object's copy constructor and assignment operator.
Move Semantics: In C++, to reduce the overhead of constructing temporary objects, the Move operation transfers ownership of an object to another object, which helps mitigate performance issues caused by creating many temporary objects during object passing.
These "magic operations" in C++ allow for flexible object passing in various scenarios, but they also increase the overall complexity of the language. In contrast, Java eliminates C/C++ pointers and uses safer references, incorporating reference counting and garbage collection to handle multiple references sharing the same memory, thus significantly reducing complexity. When passing object copies in Java, you must define your own constructor or use the clone() method from the prototype design pattern. To release a reference in Java, you explicitly set the reference variable to null. Overall, all languages must effectively manage object passing to provide a relatively flexible programming approach.
In Rust, the concept of "ownership" is reinforced. Here are the three main rules of ownership in Rust:
Every value in Rust has a variable known as its owner.
A value has only one owner at a time.
When the owner (variable) goes out of scope, the value is dropped.
What does this mean?
If you need to pass a copy of an object, you must implement the Copy trait for that object. The trait can be thought of as a special interface for objects (used for certain operational conventions, e.g., Copy for copying, Display for output similar to Java's toString(), and Drop for resource management, among others). Built-in types like integers, booleans, floating-point numbers, characters, and tuples implement Copy, allowing for bit-wise copying (shallow copy) using memcpy. For user-defined objects, you must use the Clone trait.
Thus, the concepts of Copy and Clone emerge as similar yet distinct. Copy applies to built-in types or user-defined types composed solely of Copy types, while Clone is for programmer-defined object copies. This distinction highlights the difference between shallow and deep copies: Copy signals to the compiler that the object can be bit-wise copied, whereas Clone indicates a deep copy is required.
Data structures like String, which allocate memory on the heap, do not implement Copy (since they contain a pointer, which means deep copying is semantically required). If you need to copy a String, you must explicitly call its clone() method. Otherwise, when passing function parameters or variables, ownership is transferred, leaving the original variable effectively invalid (the compiler will check for any use of a variable whose ownership has been transferred). This is similar to move semantics in C++.
Here’s an example to better illustrate Rust’s automatic ownership transfer (the code includes comments for clarification):
// takes_ownership takes ownership of the parameter passed in, and since it does not return it, the variable cannot be accessed afterward
fn takes_ownership(some_string: String) {
println!("{}", some_string);
} // here, some_string goes out of scope and calls the drop method. The occupied memory is released.
// gives_ownership returns a value to the calling function
fn gives_ownership() -> String {
let some_string = String::from("hello"); // some_string enters scope.
some_string // returns some_string and moves it to the calling function
}
// takes_and_gives_back takes a string and returns it
fn takes_and_gives_back(mut a_string: String) -> String {
a_string.push_str(", world");
a_string // returns a_string and moves ownership to the calling function
}
fn main() {
// gives_ownership returns a value to s1
let s1 = gives_ownership();
// ownership is moved to takes_ownership, making s1 unavailable
takes_ownership(s1);
// Uncommenting the line below will cause an error due to s1 being unavailable
// println!("s1= {}", s1);
// ^^ value borrowed here after move
let s2 = String::from("hello"); // declare s2
// s2 is moved into takes_and_gives_back, which also returns a value to s3.
// s2 becomes unavailable.
let s3 = takes_and_gives_back(s2);
// Uncommenting the line below will cause an error due to s2 being unavailable
// println!("s2={}, s3={}", s2, s3);
// ^^ value borrowed here after move
println!("s3={}", s3);
}This move semantics approach is efficient in terms of performance and safety, and Rust's compiler checks for errors involving variables whose ownership has been moved. Moreover, we can also return objects from the function stack as shown below:
fn new_person() -> Person {
let person = Person {
name : String::from("Hao Chen"),
age : 44,
sex : Sex::Male,
email: String::from("haoel@hotmail.com"),
};
return person;
}
fn main() {
let p = new_person();
}Since the object is moved, the Person object returned from the new_person() function is moved to the main() function, thus avoiding performance issues. In C++, we need to explicitly define move functions to achieve this because C++ calls the copy constructor by default, not the move constructor.
Complexity Introduced by Ownership Semantics
The ownership and move semantics can introduce some complexity. First, let's consider a scenario where we have a structure, and we move one of its members. See the code below:
#[derive(Debug)] // Allows the struct to use {:?} for output
struct Person {
name: String,
email: String,
}
let _name = p.name; // Move the struct's name
println!("{} {}", _name, p.email); // Other members can be accessed normally
println!("{:?}", p); // Compilation error: "value borrowed here after partial move"
p.name = "Hao Chen".to_string(); // Person::name is restored
println!("{:?}", p); // Compiles normally nowIn this example, we can see that a member within the struct can be moved. When a member is moved, the instance of the struct becomes partially uninitialized. If you need to access all members of the struct, a compilation error will occur. However, after restoring Person::name, everything works fine again.
Now let’s look at a more complex example—this simulates a scene in animation rendering, where we need two buffers: one for the current display and another for the next frame to be displayed.
struct Buffer {
buffer: String,
}
struct Render {
current_buffer: Buffer,
next_buffer: Buffer,
}
// Implement methods for the Render struct
impl Render {
// Implement update_buffer() method
// Update the buffer by moving next to current, then updating next
fn update_buffer(&mut self, buf: String) {
self.current_buffer = self.next_buffer; // Error occurs here
self.next_buffer = Buffer { buffer: buf };
}
}At first glance, the code looks fine, but the Rust compiler will not allow it to compile. It will throw the following error:
error[E0507]: cannot move out of self.next_buffer which is behind a mutable reference --> /.........../xxx.rs:18:31 | 14 | self.current_buffer = self.next_buffer; | ^^^^^^^^^^^^^^^^ move occurs because self.next_buffer has type Buffer, which does not implement the Copy trait
The compiler informs us that Buffer does not implement the Copy trait. However, if you implement the Copy trait, you lose the performance benefits of move semantics. This puts you in a difficult position, unsure of how to proceed.
Rust does not allow us to move a member within a method because it would leave the reference to self incomplete. Rust requires us to implement the Copy trait, but we don’t want a copy; we want to move next_buffer into current_buffer. We want to move two variables at once: we want to move buf into next_buffer while also moving the contents of next_buffer into current_buffer. We need some “juggling” skills.
This requires using the function std::mem::replace(&dest, src), which moves the value of src into dest and then returns dest. (This involves some unsafe low-level operations to complete.) Anyway, the final implementation looks like this:
use std::mem::replace;
fn update_buffer(&mut self, buf: String) {
self.current_buffer = replace(&mut self.next_buffer, Buffer { buffer: buf });
}What do you think of this “juggling” code? I feel it decreases readability significantly.
References (Borrowing) and Lifetimes
Next, let's talk about references, as moving the ownership of an object may not always be suitable. For instance, if I have a function compare(s1: Student, s2: Student) -> bool that compares the average scores of two students, I wouldn’t want to pass copies because that would be too slow, nor would I want to transfer ownership, as I only need to compute data from the objects. In this case, passing references is a better choice, and Rust supports this. You simply need to change the function declaration to compare(s1: &Student, s2: &Student) -> bool. When calling it, you would use compare(&s1, &s2);, which is similar to C++. In Rust, this is also referred to as “borrowing.” (These new terms coined by Rust semantically make things easier to understand, but they also increase the complexity of learning.)
References (Borrowing)
Moreover, if you need to modify the referenced object, you must use a “mutable reference,” such as foo(s: &mut Student) and call it with foo(&mut s). Additionally, to avoid data races, Rust strictly enforces that at any time, there can either be one mutable reference or multiple immutable references.
These strict rules can lead to a loss of programming flexibility, and programmers unfamiliar with Rust may become frustrated by certain compilation errors. However, the stability of your code will improve, and the bug rate will decrease.
Furthermore, to resolve the issue of “dangling references,” where multiple variables reference an object without using extra reference counting to increase runtime complexity, Rust manages the lifetimes of references. This management occurs at compile time, and if a reference's lifetime is problematic, an error is reported. For example:
let r;
{
let x = 10;
r = &x;
}
println!("r = {}", r);In this code, it’s visually obvious that the scope of x is smaller than that of r, which results in r being invalid during the println(). This code would compile and run normally in C++, and although it can print the value of x, that value is already problematic. In Rust, however, the compiler provides a compilation error stating, “x dropped here while still borrowed,” which is quite impressive.
However, this compile-time checking technique can become more challenging when the program becomes slightly more complex, and the compiler's checks for “dangling references” become less straightforward. For instance, consider the following code:
fn order_string(s1: &str, s2: &str) -> (&str, &str) {
if s1.len() < s2.len() {
return (s1, s2);
}
return (s2, s1);
}
let str1 = String::from("long long long long string");
let str2 = "short string";
let (long_str, short_str) = order_string(str1.as_str(), str2);
println!("long={} short={}", long_str, short_str);We have two strings, str1 and str2, and we want to use the order_string() function to return them as long_str and short_str for further processing. This is a common pattern. However, you will find that this code fails to compile. The compiler informs you that the return type of order_string() requires a lifetime parameter—“expected lifetime parameter.” This is because the Rust compiler cannot determine, through static code analysis, whether the returned references are (s1, s2) or (s2, s1), as this is decided at runtime. Therefore, it cannot ascertain the lifetimes of the two returned references in relation to s1 or s2.
Lifetimes
If your code looks like this, the compiler can infer that the parameter and return values of the function foo() are references, and their lifetimes are the same, allowing it to compile successfully:
fn foo(s: &mut String) -> &String {
s.push_str("coolshell");
s
}
let mut s = "hello, ".to_string();
println!("{}", foo(&mut s));However, when multiple references are passed in, and the return value could be any of those references, the compiler gets confused because it cannot predict runtime behavior, thus requiring the programmer to annotate lifetimes.
fn long_string<'c>(s1: &'c str, s2: &'c str) -> (&'c str, &'c str) {
if s1.len() > s2.len() {
return (s1, s2);
}
return (s2, s1);
}In the above Rust code, the lifetime annotations use a single quote followed by any string (except for 'static, which is a keyword indicating a lifetime that lasts for the entire program). This annotation specifies that the lifetimes of the returned references are the same as those of s1 and s2, effectively turning runtime issues into compile-time issues. This allows the program to compile successfully. (Note: Don’t think you can arbitrarily write lifetimes; this is just a “syntax sugar operation” to help the compiler understand lifetimes. If you violate actual lifetimes, the compiler will still refuse to compile.)
Here are two key points:
As soon as you start using references, lifetime annotations will come into play.
The Rust compiler does not know what will happen at runtime, so you must provide explicit annotations.
Feeling a bit dizzy now? Let’s add to that. For example, if you want to use references within a struct, you must declare lifetimes for the references, as shown below:
// The lifetimes of ref1 and ref2 are consistent with the struct's lifetime
struct Test<'life> {
ref_int: &'life i32,
ref_str: &'life str,
}In this case, the lifetime annotation 'life is defined at the struct level and applied to its member references. This means the rule is—“the struct's lifetime <= the lifetime of its member references.”
Then, if you want to implement two set methods for this struct, you must also include the lifetime annotations.
impl<'life> Test<'life> {
fn set_string(&mut self, s: &'life str) {
self.ref_str = s;
}
fn set_int(&mut self, i: &'life i32) {
self.ref_int = i;
}
}In the above example, the lifetime variable 'life is declared on the impl block and applies to the struct and its method parameters. This indicates the rule—“the lifetime of the struct's method parameters >= the lifetime of the struct itself.”
With these lifetime annotation rules established, Rust can happily check these rules and compile the code successfully.
Closures and Ownership
The strict separation and management of ownership and references affect many aspects of Rust. Let's now look at how these concepts are handled within function closures. Closures, also known as lambda expressions, are an essential feature of functional programming, supported by nearly all advanced languages. In Rust, closures are defined using two vertical bars (| |), with parameters placed between the bars. Here's an example:
// Defines a lambda `f(x, y) = x + y` for the operation `x + y`
let plus = |x: i32, y: i32| x + y;
// Defines another lambda `g(x) = f(x, 5)`
let plus_five = |x| plus(x, 5);
// Output
println!("plus_five(10)={}", plus_five(10));Closures
However, once ownership concepts are introduced, things get more complicated. Let’s look at the following code:
struct Person {
name: String,
age: u8,
}
fn main() {
let p = Person { name: "Hao Chen".to_string(), age: 44 };
// This works because `u8` implements the `Copy` trait
let age = |p: Person| p.age;
// `String` does not implement the `Copy` trait, so ownership is moved here
let name = |p: Person| p.name;
println!("name={}, age={}", name(p), age(p));
}The above code won't compile because when name(p) is called, ownership of p is moved. Now let's consider the modified version using references:
let age = |p: &Person| p.age;
let name = |p: &Person| &p.name;
println!("name={}, age={}", name(&p), age(&p));Even with this, the code will still not compile, and the error message reads: “cannot infer an appropriate lifetime for borrow expression due to conflicting requirements.”
error[E0495]: cannot infer an appropriate lifetime for borrow expression due to conflicting requirements --> src/main.rs:11:31 | 11 | let name = |p: &Person| &p.name; | ^^^^^^^
You might start trying to add lifetime annotations and experiment with various Rust tricks (as seen in Rust’s GitHub issue #58052), but the code still won’t compile. Eventually, you might turn to StackOverflow and find the correct solution (this could also be related to bug #41078). However, the resulting code is far from clean:
// The following declaration works let name: for<'a> fn(&'a Person) -> &'a String = |p: &Person| &p.name;
This lifetime annotation is somewhat peculiar. It uses a function type annotation, which requires the for<'a> keyword. You might feel confused by this keyword—after all, isn’t for used for loops? Indeed, Rust's reusing of keywords like this introduces unnecessary complexity, in my opinion. Overall, this declaration is something most people wouldn’t come up with—this “syntax sugar removal” has gone too far, and most developers won’t be able to handle it!
Now, let’s consider another issue. The following code also fails to compile:
let s = String::from("coolshell");
let take_str = || s;
println!("{}", s); // ERROR
println!("{}", take_str()); // OKThe Rust compiler will inform you that take_str has taken ownership of s (because it needs to return the value). As a result, the later print statement becomes unusable. This means:
For built-in types that implement the
Copytrait, closures perform borrowing.For types that do not implement
Copy, methods can be called within the closure (borrowing), but they cannot be returned from the closure. If returned, ownership is moved.
Although there are these “implicit rules,” they don’t satisfy all situations, so programmers need to define explicit “move” rules. The following code illustrates the difference between a closure with and without the move keyword:
// ---------- Borrowing case ----------
let mut num = 5;
{
let mut add_num = |x: i32| num += x;
add_num(5);
}
println!("num={}", num); // Outputs 10
// ---------- Move case ----------
let mut num = 5;
{
// Move ownership of `num` into `add_num` as a local variable within the closure
let mut add_num = move |x: i32| num += x;
add_num(5);
println!("num(move)={}", num); // Outputs 10
}
// Since `i32` implements the `Copy` trait, `num` is still accessible
println!("num(move)={}", num); // Outputs 5It can be confusing, especially with types like int that implement the Copy trait. When ownership is moved, the num inside the block and the num outside are two separate variables. However, when reading the code, your brain might not see it this way, as the inner num isn’t explicitly declared—it appears to be the same as the outer num. I personally find this to be one of the many “whack-a-mole” problems in Rust.
Thread Closures
From the above example, we can see that the move keyword allows a variable from outside the closure to be moved into the closure, making it a local variable inside the closure. This ensures safer execution in a multithreaded environment, as seen in the following example:
let name = "CoolShell".to_string();
let t = thread::spawn(move || {
println!("Hello, {}", name);
});
println!("wait {:?}", t.join());First, closures inside thread::spawn() cannot take parameters. However, since it's a closure, it can access variables within its visible scope. But because it’s a different thread, this means data is being shared across threads (such as the main thread), so Rust requires that variables be moved into the thread to ensure safety—this guarantees that name will never expire within the thread and won’t be modified by anyone else.
You might have some questions, such as:
The
namevariable is not declared asmut, which means it’s immutable. Isn’t it safe without using themovekeyword?What if I want to pass
nameto multiple threads?
Yes, it is safe, but Rust threads must be move, regardless of whether they are mutable. If you want to pass a variable to multiple threads, you need to create a copy of the variable by calling the clone() method.
let name = "CoolShell".to_string();
let name1 = name.clone();
let t1 = thread::spawn(move || {
println!("Hello, {}", name.clone());
});
let t2 = thread::spawn(move || {
println!("Hello, {}", name1.clone());
});
println!("wait t1={:?}, t2={:?}", t1.join(), t2.join());Now you might ask, isn’t cloning expensive? Imagine if I wanted to use multiple threads to process a large array. This cloning approach wouldn’t be feasible. In that case, you would need to use another technique: smart pointers.
Rust's Smart Pointers
If you're still not confused at this point, then my article has been somewhat successful (if you are confused, please let me know, and I'll make improvements). Next, let’s talk about Rust’s smart pointers and polymorphism.
Some memory needs to be allocated on the heap rather than the stack. Memory on the stack is generally determined at compile time, meaning the compiler needs to know the size of your arrays, structs, enums, and other data types. Without this information, compilation is impossible. Additionally, the memory size cannot be too large, as the stack has limited space. Too large of an allocation could result in a stack overflow error. For larger or dynamically allocated memory, the heap is required. Those familiar with C/C++ will recognize this concept.
As a memory-safe language, Rust also needs to manage memory allocated on the heap. In C, the programmer must manage this memory manually, whereas in C++, the RAII mechanism (Resource Acquisition Is Initialization, an object-oriented proxy pattern) is commonly used. This technique involves managing heap memory with objects allocated on the stack. In C++, this technique is implemented with "smart pointers."
In C++11, there are three types of smart pointers (I won’t go into detail on them here):
unique_ptr: Exclusive ownership of memory, no sharing. In Rust, this is:std::boxed::Boxshared_ptr: Shared memory via reference counting. In Rust, this is:std::rc::Rcweak_ptr: Weak reference to shared memory (without affecting reference count). In Rust, this is:std::rc::Weak
I won’t discuss the exclusive Box in detail here, but let’s focus on the shared Rc and Weak pointers:
For Rust's
Rc, the pointer contains astrong_countreference counter. When the reference count drops to 0, the memory is automatically released.When memory needs to be shared, the
clone()method is called on the instance, like this:let another = rc.clone(). Cloning only increments the reference count, it does not perform a deep copy (in my opinion, the semantics ofcloneare somewhat violated here).With reference counting, multithreading becomes an issue. If you need thread-safe smart pointers, you should use
std::sync::Arc.You can call
Rc::downgrade(&rc)to convert a strong reference into aWeakpointer. TheWeakpointer increments theweak_count, and the memory is not checked for release when it drops to 0.
Here’s a simple example:
use std::rc::Rc;
use std::rc::Weak;
// Declare two uninitialized pointer variables
let weak: Weak;
let strong: Rc;
{
let five = Rc::new(5); // Local variable
strong = five.clone(); // Create a strong reference
weak = Rc::downgrade(&five); // Create a weak reference to the local variable
}
// At this point, `five` has been dropped, so `Rc::strong_count(&strong) = 1` and `Rc::weak_count(&strong) = 1`
// If `drop(strong)` is called, the entire memory will be released
// drop(strong);
// To access the value of a weak reference, it needs to be "upgraded" to a strong reference for safe usage
match weak.upgrade() {
Some(r) => println!("{}", r),
None => println!("None"),
}This simple example primarily shows the shared nature of pointers. Since the pointer is shared, it is safe for the last person holding the strong reference to release it. However, for weak references, this creates a problem. Strong references have ownership, but weak references do not. If you release the memory, how would a weak reference know?
Thus, when weak references need to use the memory, they must "upgrade" to a strong reference. This upgrade might fail because the memory may already have been cleared by someone else. As a result, the upgrade operation returns an Option enum, where Option::Some(T) indicates success, and Option::None indicates failure. You might wonder, "Why bother with Weak if it's so troublesome?" It's because Rc with strong references can lead to cyclic references (those who have studied C++ should be familiar with this).
Additionally, if you need to modify the value inside an Rc, Rust provides two methods: get_mut() and make_mut(). Both methods come with side effects or restrictions.
get_mut()requires a "unique reference" check, meaning there can be no sharing before modification.
// Modify the referenced variable – `get_mut` returns an `Option` object.
// Note that modification is only allowed when (there is only one strong reference && no weak references).
if let Some(val) = Rc::get_mut(&mut strong) {
*val = 555;
}make_mut()will clone the current reference, making it no longer shared. It creates a completely new copy.
// You can modify the reference here, but it uses cloning, meaning that `strong` is now independent. *Rc::make_mut(&mut strong) = 555;
If you don’t handle this correctly, you could run into many memory safety issues. Pay close attention to these small details; otherwise, you might find yourself completely baffled by how your code is running.
If you want a more flexible experience with smart pointers, there’s another option—Cell and RefCell. These help compensate for the ownership system's limitations in certain scenarios, providing set()/get() and borrow()/borrow_mut() methods. These allow your program to be more flexible without being overly constrained. See the following example:
use std::cell::Cell;
use std::cell::RefCell;
let x = Cell::new(1);
let y = &x; // Reference (borrowing)
let z = &x; // Reference (borrowing)
x.set(2); // Can modify, and `x`, `y`, `z` will all reflect the change.
y.set(3);
z.set(4);
println!("x={} y={} z={}", x.get(), y.get(), z.get());
let x = RefCell::new(vec![1, 2, 3, 4]);
{
println!("{:?}", *x.borrow());
}
{
let mut my_ref = x.borrow_mut();
my_ref.push(1);
}
println!("{:?}", *x.borrow());As you can see from the examples above, it becomes more convenient to use smart pointers. However, it’s important to note that Cell and RefCell are not thread-safe. In multithreading, you’ll need to use Mutex for mutual exclusion.