DeepSeek V3 sets a new benchmark in open-source AI, achieving state-of-the-art performance with a fraction of the cost and resources. From surpassing Llama 3.1 to revolutionizing inference speed and training costs, this Chinese innovation challenges Silicon Valley's dominance while fostering global advancements in AI accessibility and efficiency.
The launch of the large model DeepSeek V3 became the true highlight of the AI world in 2024.
The release was open-source from the get-go, and here’s just how cool it is: reaching open-source SOTA, surpassing Llama 3.1 405B; with about a third of the parameters of GPT-4o, but costing only 9% of Claude 3.5 Sonnet’s price. Yet, its performance rivals that of these top-tier closed-source models 💪.
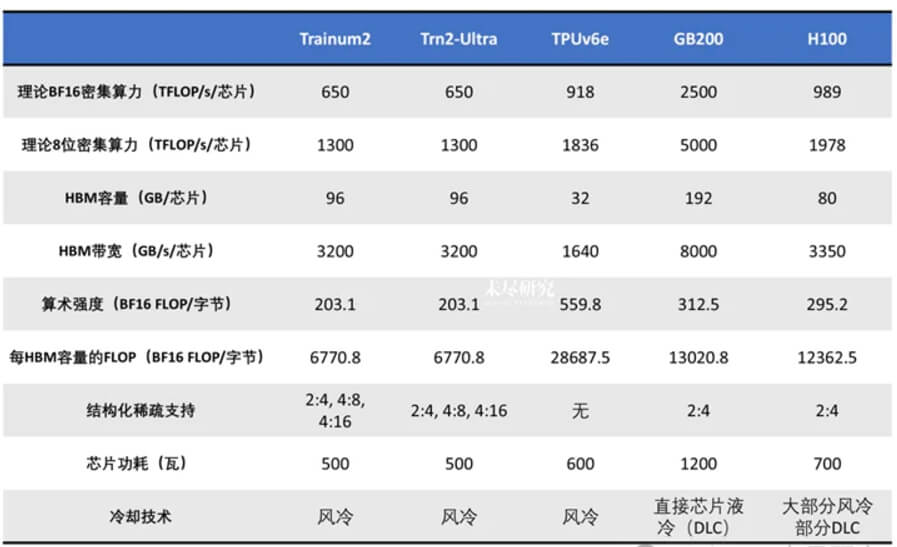
The entire training process took less than 2.8 million GPU hours, whereas Llama 3 405B took 30.8 million GPU hours (Note: Llama uses H100, whereas DeepSeek uses a scaled-down version, the H800). With 60 tokens generated per second, DeepSeek V3 is 3x faster than its previous version. The total cost of training the 671B model was only $5.576 million — affordable for any startup!
A “Bitter Lesson” for Silicon Valley 🍂
DeepSeek V3’s inference and training costs are only a tenth of those of top Silicon Valley models, which has left Silicon Valley a bit stunned 🤯. OpenAI’s 12-day product release marathon was interrupted by Google, and now, just as they were gearing up for the Christmas and New Year holidays, they’re hit with this bombshell.
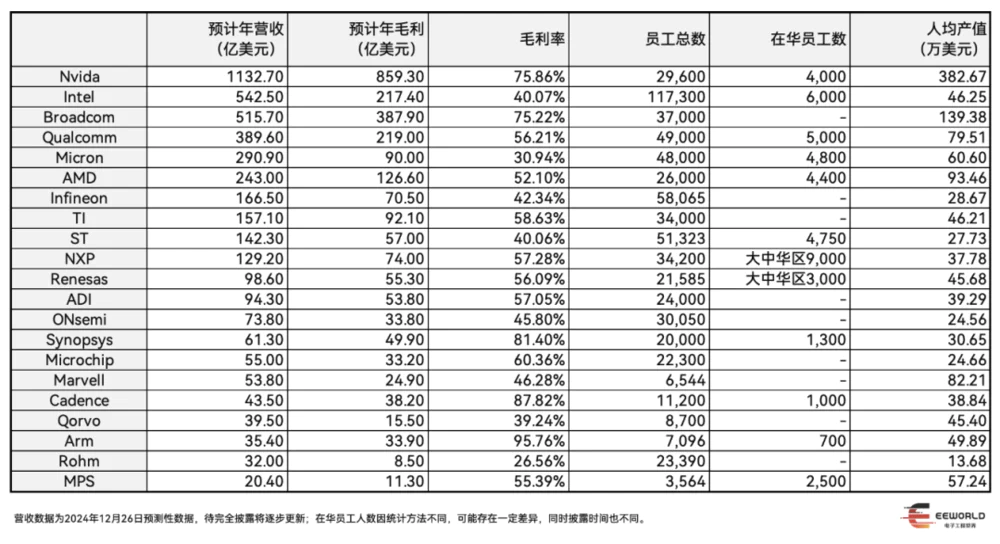
They also found out that DeepSeek had only 139 engineers and researchers, including founder Liang Wenfeng, working on this project. In comparison, OpenAI employs 1,200 researchers, and Anthropic has 500.
Alex Wang, the founder of AI unicorn company scale.ai, remarked: “A bitter lesson from China’s technology: while Americans are resting, they are working and catching up with cheaper, faster, and stronger products.”
Even AI luminaries like Karpathy, Meta scientist Tian Yuandong, Tim Dettmers (the inventor of QLora), and OpenAI scientist Sebastian Raschka have given kudos.
Some Comments from the AI Community:
“DeepSeek v3 might be more significant for China than the 6th generation fighter jet: a Chinese AI model that competes with and often surpasses the latest ChatGPT and Claude models in almost every aspect, but with training costs only a tiny fraction (just $5.5 million), and it’s open-source (meaning anyone can use, modify, and improve it).”
“The low training cost is crucial because it changes the game about who can participate in advanced AI development. It was generally believed that training such models required hundreds of millions or even billions of dollars, but DeepSeek did it with just $5.5 million — something nearly any startup can afford. This proves that serious AI development is no longer confined to tech giants.”
The Closing of 2024 — A Stark Reminder for Silicon Valley:
The end of 2024 serves as a sharp reminder to Silicon Valley: the U.S. tech blockade on China, including the harshest chip and AI restrictions, has resulted in resource shortages that have sparked an innovative surge among Chinese tech companies.
In April 2023, Huanfang, a quantitative investment fund based in Hangzhou, announced their intention to work on large models. In May 2023, they spun off the large model team to form DeepSeek. In 2021, Huanfang was one of the first in the Asia-Pacific region to obtain A100 GPUs, becoming one of the few institutions in China to own thousands of A100 GPUs. Since the ChatGPT era, there has been a pervasive "GPU-only" mentality in the industry, with thousands of cards and hundreds of millions of dollars seen as the threshold for large models.
From the start, DeepSeek announced it was working on AGI, focusing on large models — starting with language models and then expanding into vision and multimodal models. In early 2024, they launched their first large language model, DeepSeek LLM, which could only compete with GPT-3.5. But by the end of 2024, DeepSeek V3 was already going head-to-head with GPT-4o, and entering the multimodal and reasoning model arena.
DeepSeek's 2024 Journey 🏆
DeepSeek is one of the few teams in China and even globally with both strong infrastructure engineering capabilities and model research expertise. DeepSeek is fully open-source, and from the 8 research papers they published in 2024, we can see how, in just one year, a Chinese AI company that relies entirely on domestic talent has learned and caught up with Silicon Valley's AI giants.
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (January 5)
DeepSeek’s first large model, DeepSeek LLM, contains 67 billion parameters and was trained from scratch on a 2 trillion token dataset in both Chinese and English. It outperformed Llama 2 70B in inference, coding, math, and Chinese comprehension. It even scored 65 on Hungary's national high school exam and surpassed GPT-3.5 in Chinese.DeepSeek-Coder: When the Large Language Model Meets Programming — The Rise of Code Intelligence (January 25)
DeepSeek-Coder is a series of code models trained on 2 trillion tokens, with 87% code and 13% natural language. It reached state-of-the-art performance for open-source code models in various programming languages and benchmarks.DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (February 5)
Based on DeepSeek-Coder-v1.5 7B, DeepSeekMath was trained on math-related tokens from Common Crawl and achieved excellent results in the competitive MATH benchmark, nearing the performance of Gemini-Ultra and GPT-4.
DeepSeek-VL: Towards Real-World Vision-Language Understanding (March 11)
An open-source vision-language model that can efficiently process high-resolution images while maintaining low computational overhead. It achieved competitive performance in vision-language tasks with model sizes of 1.3B and 7B.DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (May 7)
DeepSeek-V2 is an MoE language model that is both powerful and cost-effective. It contains 236 billion parameters and outperforms DeepSeek 67B in performance while cutting training costs by 42.5%. It also reduces KV cache usage by 93.3% and boosts throughput by 5.76x.
The Price War Sparked by DeepSeek V2 🔥
The launch of DeepSeek V2 sparked a price war in China’s hundred-model competition, driving down inference costs to just 1 RMB per million tokens, roughly 1/7th of Llama 3 70B’s cost and 1/70th of GPT-4 Turbo’s. Silicon Valley was stunned 😱.
Semianalysis, a renowned semiconductor and AI consultancy, quickly recognized that DeepSeek could be a serious contender to OpenAI and might even crush other open-source models.
They noted that DeepSeek’s innovative architecture, especially in areas like Mixture-of-Experts (MoE), Rotary Position Encoding (RoPE), and Attention mechanisms, introduced new advancements. DeepSeek even implemented a novel Multi-Head Latent Attention mechanism, claiming better scalability and higher accuracy than other forms of attention mechanisms.
Semianalysis also calculated that DeepSeek’s large model services could yield a gross margin of over 70%, thanks to its cost-effective infrastructure: “Even with imperfect server utilization, DeepSeek has enough room to crush all competitors in reasoning economics and still make a profit.”
On the basis of V2, DeepSeek quickly rolled out Coder-V2 and VL2.
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence (June 17th)
DeepSeek-Coder-V2 is an open-source Mixture-of-Experts (MoE) code language model that achieves performance on par with GPT-4 Turbo for code-specific tasks. Starting from an intermediate checkpoint of DeepSeek-V2, it underwent further pretraining with an additional 6 trillion tokens, significantly enhancing its coding and mathematical reasoning capabilities while maintaining strong performance in general language tasks. It demonstrated remarkable improvements across code-related tasks, reasoning capabilities, and general competencies. Additionally, DeepSeek-Coder-V2 expanded its support for programming languages from 86 to 338 and extended the context length from 16K to 128K. In standard benchmarks, it outperformed closed-source models like GPT-4 Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and mathematical tasks. 💻✨
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding (December 13th)
DeepSeek-VL2 is an advanced series of large-scale Mixture-of-Experts (MoE) vision-language models that present significant improvements over its predecessor, DeepSeek-VL. It excels in a wide range of tasks, including visual question answering, optical character recognition, document/table/chart understanding, and visual localization. The series includes three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small, and DeepSeek-VL2, with 1 billion, 2.8 billion, and 4.5 billion activated parameters, respectively. Compared to existing open-source dense and MoE-based models, DeepSeek-VL2 delivers competitive or state-of-the-art performance with similar or fewer activated parameters. 📸🤖

DeepSeek-V3: A Breakthrough in Inference Speed and Performance (December 26th)
DeepSeek-V3 is a powerful Mixture-of-Experts (MoE) language model featuring 671 billion total parameters, with 37 billion parameters activated per token. To ensure efficient inference and cost-effective training, it employs Multi-Head Latent Attention (MLA) and the proven DeepSeek MoE architecture. It also introduced an innovative loss-free load-balancing strategy and multi-token prediction training objectives to boost performance. The model was pretrained on 148 trillion diverse, high-quality tokens, followed by supervised fine-tuning and reinforcement learning phases to unlock its full potential. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves parity with leading closed-source models. Its training was remarkably stable, with no unrecoverable loss spikes or rollbacks throughout the process. 🚀📚
Notably, DeepSeek launched its search functionality on December 10th, a week ahead of SearchGPT's official release.
Does DeepSeek Have 50,000 H100 GPUs?
When DeepSeek released the R1-Lite preview inference model on November 20th—just two months after OpenAI’s release of the o1 preview model—Dylan Patel, founder of SemiAnalysis, couldn’t hold back: “Without 50,000 H100 GPUs, who could pull this off?!”
He added, "People need to stop assuming they’re just working with that 10,000 A100 GPU cluster. Their strength lies not only in machine learning research but also in exceptional infrastructure management, despite using significantly fewer GPUs."

DeepSeek's founder, Liang Wenfeng, shared in an interview with Dark Current Media:
“We don’t set limits on the allocation of GPUs or personnel. If anyone has an idea, they can access the training cluster anytime without approval.”
While details on how R1-Lite was trained, including GPU quantity and types, remain unpublished, DeepSeek has announced plans to release an official technical report and open its API soon.
Two Years Ago, China Felt Left Behind... Now, It's a Different Story
Two years ago, as China was emerging from three years of pandemic restrictions, the world witnessed the rise of the ChatGPT moment, leading many to believe a massive technological wave had left them behind. But by 2024, while OpenAI paused innovation with ChatGPT-4, its advancements—from video generation (Sora) to inference models (o1)—have been matched or approached by Chinese AI firms at just one-tenth of the cost. Could the stories of electric vehicles and drones be repeating in the AI domain? 🌍✨
Looking Ahead to 2025
The race between global AI leaders is far from over. With innovations from all sides, 2025 promises to be a thrilling year. 🏁🤖