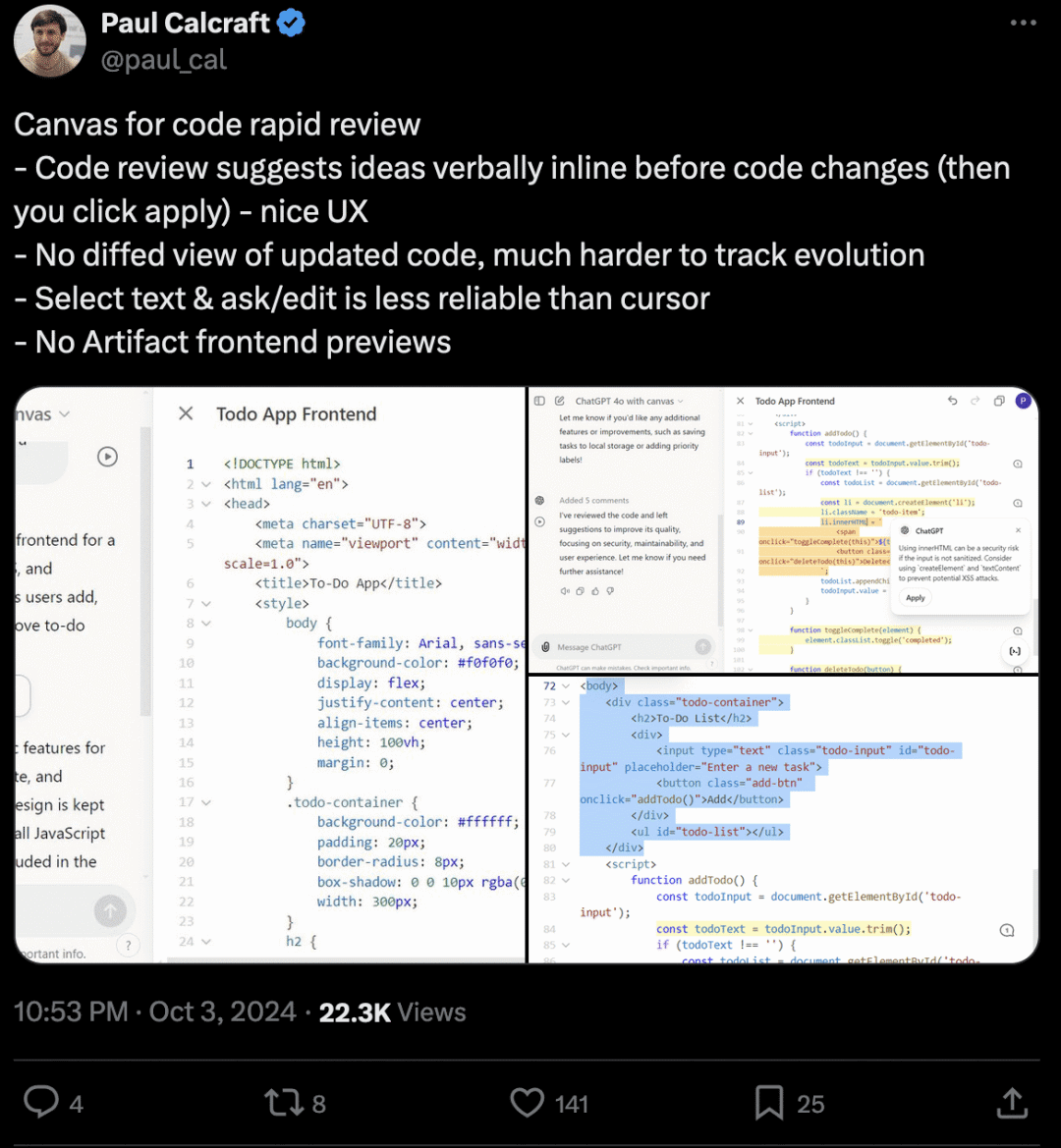
In the world of deep learning, PyTorch, TensorFlow, and Keras are the most popular tools and frameworks, offering powerful and easy-to-use interfaces for researchers and developers. In this article, we will explore these three frameworks in depth, covering how to implement classic deep learning models with them, and provide detailed code examples for their usage.

1. Introduction and Comparison of Deep Learning Frameworks
Before diving into the details of each framework, let’s first take a brief look at the characteristics and advantages of PyTorch, TensorFlow, and Keras.
PyTorch Introduction
PyTorch is an open-source deep learning framework developed by Facebook's AI research team. It features dynamic computation graphs, allowing users to build and debug models flexibly. Its object-oriented design and Pythonic coding style make it highly popular among developers and researchers.
Advantages:
Dynamic computation graph, very flexible and easy to debug.
Strong community support, especially in research.
Easy to integrate with Python libraries such as Numpy.
TensorFlow Introduction
TensorFlow is a widely used deep learning framework developed by Google, applied extensively in both industry and academia. Since TensorFlow 2.0, it has become easier to use and supports Keras-based APIs to simplify model development.
Advantages:
A rich toolset and ecosystem, including TensorBoard, TF-Hub, etc.
Excellent support for production deployment and large-scale distributed training.
Supports both static and dynamic graphs.
Keras Introduction
Keras was originally an independent high-level API designed to simplify building and training deep learning models. It is now integrated into TensorFlow as its high-level interface, enabling users to quickly design and implement model prototypes.
Advantages:
Minimalist and clear API, suitable for beginners and rapid prototyping.
Easy integration with TensorFlow.
2. Getting Started with PyTorch
2.1 Installing PyTorch and Basic Setup
First, let’s look at how to install PyTorch and set up the development environment. Installing PyTorch on your system is simple and can be done using the following command:
pip install torch torchvision
You can also install torchvision for handling image data.
2.2 Building a Simple Neural Network
Let’s implement a simple neural network using PyTorch. Below is a simple model for MNIST handwritten digit classification:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets, transforms
# Define dataset loader
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Define neural network model
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# Instantiate model, loss function, and optimizer
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Train the model
epochs = 5
for e in range(epochs):
running_loss = 0
for images, labels in trainloader:
optimizer.zero_grad()
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {e+1}, Loss: {running_loss/len(trainloader)}')In the code above, we use a simple three-layer fully connected network to classify MNIST digits and train it for 5 epochs.
2.3 Advantages and Features of PyTorch
Flexibility: The dynamic computation graph makes debugging and development more flexible.
Concise API: The code style is Pythonic, making it easy to read and understand.
2.4 Advanced Features: Using GPUs for Training
PyTorch supports GPU acceleration, and it’s very easy to move your model and data to the GPU:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
# Continue training steps...3. Basic Usage of TensorFlow 2.0
3.1 Installing TensorFlow
You can install TensorFlow 2.0 with the following command:
pip install tensorflow
3.2 Building a Simple Neural Network
Let’s implement a model using TensorFlow 2.0, similar to the PyTorch model, for MNIST digit classification:
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# Load and preprocess data
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1)).astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Build the model
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(train_images, train_labels, epochs=5, batch_size=64, validation_data=(test_images, test_labels))In TensorFlow, we used the Keras API to build a convolutional neural network, which makes defining and training models very simple.
4. Quick Start with Keras API
4.1 Basic Concepts of Keras
Keras is designed to be simple and modular. It’s a high-level neural network API where users can focus on model construction without worrying too much about the underlying details. Keras is now integrated into TensorFlow as its high-level interface.
4.2 Building Models with Keras
The following code demonstrates how to use Keras to implement a simple fully connected neural network for classification tasks:
from tensorflow.keras import models, layers
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# Load the dataset
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28)).astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Build the model
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(train_images, train_labels, epochs=5, batch_size=128, validation_data=(test_images, test_labels))4.3 Transfer Learning with Keras
Keras is great for transfer learning. Here’s an example of using the pre-trained VGG16 network for transfer learning:
from tensorflow.keras.applications import VGG16 from tensorflow.keras import models, layers # Load the pre-trained VGG16 model (without the top fully connected layers) base_model = VGG16(weights='imagenet', include_top=False, input_shape=(150, 150, 3)) # Freeze all layers of the pre-trained model for layer in base_model.layers: layer.trainable = False # Add custom fully connected layers model = models.Sequential() model.add(base_model) model.add(layers.Flatten()) model.add(layers.Dense(256, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) # Compile the model model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
5. Model Debugging and Optimization
In deep learning, debugging and optimizing models are critical steps. Below are some commonly used techniques:
5.1 Using Learning Rate Schedulers
Adjusting the learning rate during training can help the model converge more effectively:
lr_schedule = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-3 * 10 ** (epoch / 20)) model.fit(train_images, train_labels, epochs=10, callbacks=[lr_schedule])
5.2 Early Stopping
Early stopping prevents the model from overfitting:
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3) model.fit(train_images, train_labels, epochs=50, validation_data=(test_images, test_labels), callbacks=[early_stopping])
6. Practical Applications
6.1 Image Classification
Using convolutional neural networks (CNNs) for image classification is a classic application of deep learning. Pretrained models such as ResNet and VGG enable us to quickly implement high-accuracy classifiers.
6.2 Natural Language Processing (NLP)
Deep learning has achieved significant breakthroughs in NLP with Transformer architectures such as BERT and GPT. Below is a simple example of implementing a text classification model using TensorFlow:
from tensorflow.keras.preprocessing.text import Tokenizer from tensorflow.keras.preprocessing.sequence import pad_sequences sentences = ["I love machine learning", "Deep learning is amazing"] labels = [1, 0] # Tokenization and padding tokenizer = Tokenizer(num_words=1000) tokenizer.fit_on_texts(sentences) sequences = tokenizer.texts_to_sequences(sentences) padded = pad_sequences(sequences, maxlen=5)
7. Advanced Features of Deep Learning Frameworks
7.1 Distributed Training
Both TensorFlow and PyTorch support distributed training, enabling the acceleration of model training across multiple GPUs or nodes.
strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = models.Sequential() model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,))) model.add(layers.Dense(10, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(train_images, train_labels, epochs=5, batch_size=128)
8. Conclusion
In this article, we explored three popular deep learning frameworks: PyTorch, TensorFlow, and Keras. Through example code, we demonstrated how to use these frameworks to implement classic deep learning models. Additionally, we introduced techniques for model debugging, optimization, transfer learning, and real-world application scenarios.
PyTorch stands out for its flexibility and dynamic nature, making it ideal for researchers.
TensorFlow is favored by developers for its support for production deployment.
Keras, with its simplicity, is particularly suited for beginners and rapid prototyping.
We hope this article helps you better understand these frameworks and provides guidance for choosing the right tool. If you're interested, try using these frameworks to build your own deep learning projects and explore their advanced features.