Deep learning is a machine learning method that allows us to train artificial intelligence (AI) to predict outputs given a set of inputs (i.e., information fed into or out of a computer). AI can be trained using both supervised and unsupervised learning.
1. The Development of Deep Learning
1.1 Turing Test
The Turing Test is a standard for determining whether AI can truly succeed. British mathematician Alan Turing, the "father of computer science" and "father of artificial intelligence," introduced the concept in his 1950 paper "Can Machines Think?" In this test, a person and a computer are placed in separate rooms. An interrogator outside asks both the same questions. If the interrogator cannot distinguish between the person and the computer, it demonstrates that the computer has artificial intelligence.
1.2 Discoveries in Medicine
In 1981, the Nobel Prize was awarded to David Hubel, Torsten Wiesel, and Roger Sperry for their discoveries about how the human visual system processes information in layers. From the retina (where basic edge features are detected), through the V1 area (extracting basic shapes), to higher regions like the PFC (prefrontal cortex) for object recognition and categorization, the visual processing system becomes progressively abstract. The human brain, in this way, resembles a deep architecture, with higher-level features representing combinations of lower-level ones.
This hierarchy of features:
Edge features → Basic shapes and local object features → Complete object recognition
This layered structure mirrors our common understanding, as complex shapes are often built from basic components. It suggests that human cognition itself is deep, with features becoming increasingly abstract as processing advances.

Schematic diagram of human brain neurons

The process of computer recognition of images
1.3 The Emergence of Deep Learning
In deep learning, low-level features are combined to form more abstract high-level ones. For instance, in computer vision, deep learning algorithms learn low-level representations like edge detectors from raw images. Then, through linear or nonlinear combinations, they form high-level representations. This principle holds not just for images, but also for sounds. Researchers have found 20 fundamental sound structures in a sound database, from which other sounds can be synthesized!
2. Machine Learning
Machine learning is a means of achieving AI and is currently considered one of the most effective approaches. Machine learning is widely applied in fields like computer vision, natural language processing, and recommendation systems. Examples include highway ETC plate recognition, news recommendations on platforms like Toutiao, and product reviews on platforms like Tmall.
Simply put, machine learning involves using algorithms to enable machines to learn from large amounts of historical data, allowing them to recognize new samples or make predictions about the future.
2.1 Artificial Intelligence vs. Machine Learning
AI is a branch of computer science that simulates intelligent behavior in computers. Whenever a machine performs a task based on predefined rules, this is considered AI. In the past, developers would encode many rules that computers had to follow, forming a specific list of possible actions for the computer to make decisions.
AI today is a broad term covering everything from sophisticated algorithms to actual robots. AI can be categorized into different levels:
Weak AI: Also known as narrow AI, this refers to AI systems designed and trained for specific tasks, such as virtual personal assistants like Apple's Siri.
Strong AI: Also known as artificial general intelligence, this is an AI system with general human cognitive abilities, capable of finding solutions to unfamiliar tasks.
Machine learning, a subset of AI, refers to computers learning from large datasets rather than following hardcoded rules. Machine learning allows computers to learn by themselves, taking advantage of modern computing power to process massive datasets.
2.2 Supervised vs. Unsupervised Learning
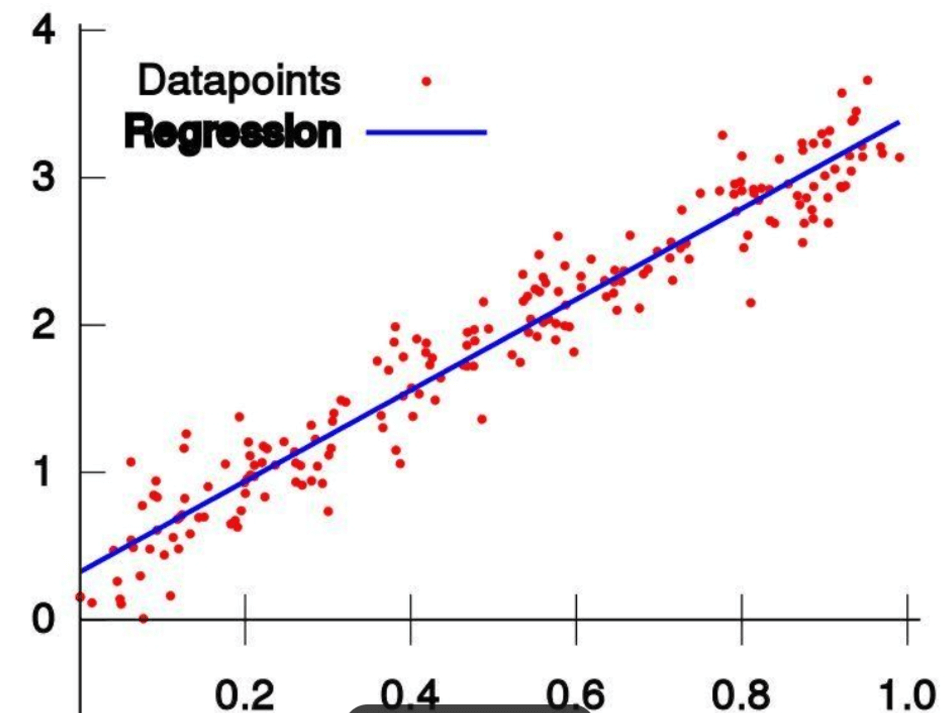
Supervised Learning: This method involves using labeled datasets with known inputs and expected outputs. When training AI with supervised learning, you provide input data and tell it the expected output. If the AI produces an incorrect result, it adjusts its calculations accordingly. This process is repeated iteratively until the AI no longer makes mistakes.
An example of supervised learning is weather forecasting AI, which learns from historical data to predict future weather conditions.
Unsupervised Learning: This approach uses unclassified, unlabeled data. The AI groups information based on patterns, similarities, and differences without prior labeling or guidance. An example is behavior-predicting AI on e-commerce platforms like Amazon, which helps identify which users are likely to buy different products.
3. How Deep Learning Works
Deep learning is a subset of machine learning that allows us to train AI to predict outputs given a set of inputs, using both supervised and unsupervised methods. A useful analogy from Andrew Ng is that deep learning models are like rocket engines, and the vast amount of data we provide to these algorithms is the fuel.
To understand how deep learning works, let's imagine building an online service that estimates bus fares. We’ll use supervised learning for training.
We want our AI to predict prices based on inputs like departure station, destination, departure date, and bus company.

3.1 Neural Networks
Neural networks are algorithms that mimic the human brain for pattern recognition. The term comes from the inspiration behind these systems' architecture: the neural structure of the biological brain. In AI, "neurons" are connected, forming layers:

Input Layer: Receives the input data. For our bus fare estimator, there are four neurons representing departure station, destination, date, and bus company.
Hidden Layer: Performs mathematical calculations on the input data. A challenge in building neural networks is determining the number of hidden layers and the number of neurons in each.
Output Layer: Produces the final output—in this case, the predicted fare.

Each connection between neurons has a weight representing the importance of the input value. The model's goal is to learn how much each element contributes to the price, which is reflected in the weights.

3.2 Improving Neural Networks Through Training
To improve our fare estimator’s accuracy, we need large amounts of computational power and data. AI is trained by comparing its predicted output with the actual output from past data. As AI is "new," its initial outputs may be wrong. By continuously adjusting the model, we reduce errors over time.
3.3 Reducing Cost Functions
The goal is to minimize the cost function, which measures the accuracy of the model. To reduce the cost function value, we use a method called gradient descent, which identifies the direction of the minimum value. Multiple passes through the dataset are needed, which is why significant computational power is required.

Once trained, the AI can predict future bus fares based on input data.