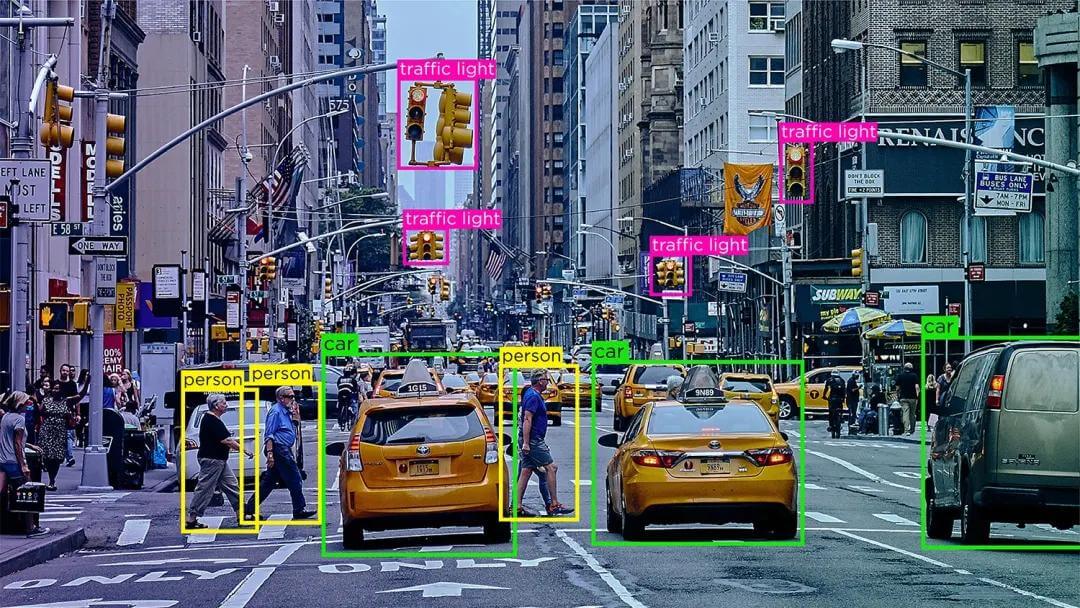
Google has unveiled Gemini 2.0, introducing cutting-edge Agent capabilities, including autonomous web browsing, natural language coding, and real-time gaming support. This marks a bold step into AI-driven automation and productivity enhancement.
As 2024 comes to a close, it seems like the major AI companies have decided to stir things up again.
After OpenAI announced its 12-day update marathon, Google chose to release its new Gemini 2.0 model on the night of December 11, just before OpenAI's update was published.
After several releases that were precisely targeted by OpenAI, Google managed to land a counterpunch tonight with Gemini 2.0, directly targeting Agent usage, a field OpenAI has yet to clearly define—there were rumors that OpenAI would launch an Agent capable of using computers next year.
The Agent function, also known as the intelligent agent feature, typically refers to AI’s ability to perceive the environment, perform tasks, and make decisions autonomously to some extent, meaning it can automate tasks more effectively.
Google seems to have made the right bet this time. OpenAI's release at 2 a.m. primarily announced its collaboration with Apple Intelligence, which is generally expected to have a strong connection with Agent capabilities. However, OpenAI's release still focused mostly on text generation and visual intelligence, with no mention of Agent-related features.
Meanwhile, Google released four Agent-related functions at once:
-
Project Astra: Allows users to directly call Google Lens and Maps in Gemini apps to solve problems.
-
Project Mariner: A Chrome browser experimental feature that helps users browse the web and perform tasks directly using prompts.
-
Jules: An embedded GitHub programming agent that can generate code that can be merged into GitHub projects using natural language descriptions.
-
Game Agent: Interprets screen content in real-time and provides gameplay strategy suggestions through voice interaction while gaming.
Although the functions released by Google are in the experimental stage, they are still very exciting. We seem to be catching a glimpse of the true arrival of the Agent era, impacting a part of human life.
1. Explosive New Agent Features: Look Up Information, Write Code, Teach You to Play Games
Google’s new features are built on the capabilities of the Gemini 2.0 model.
Unlike most large models, Google chose to train its model natively using a multimodal approach from the beginning—OpenAI only became a native multimodal model with GPT-4.
A native multimodal model refers to training a model by inputting multiple types of data, such as images, text, audio, and even video, during the training phase. This allows the model to generate content across different modalities more flexibly after understanding a "concept."
Gemini 2.0 further upgrades its native multimodal capabilities, with direct native image generation, audio output, and tool application abilities. These tool application capabilities are highly related to the Agent function. Google also improved multimodal reasoning, long-context understanding, complex command execution, function calling, local tool usage, and latency reduction.
Here’s an overview of Google’s new function demonstrations:
Project Mariner was the most surprising demo for me.
The reason is that, unlike other features, Google Chrome is a tool I use daily, and it has a significant impact on my work efficiency. Google’s experimental feature seems to require no additional configuration for the browser—just an extension.
Google cleverly chose a productivity scenario: opening a spreadsheet (Google Docs was used in the demo, though it’s unclear whether this influenced the final success of the recognition). The feature allows Chrome to remember a list of company names and search for their email addresses.
The browser automatically opens web pages, clicks on each company’s official site, finds the email address, remembers it, closes the page, and moves on to the next one. The user can see the model’s thinking process on the sidebar and can stop the automation anytime. The model only runs in the foreground to ensure safety, which, while consuming time, improves productivity—searching emails individually is a monotonous task.
Jules brings us a step closer to writing code using natural language.
In the demo, the user provided a detailed description of a programming problem, specifying which file the issue occurred in and what modifications were desired. After analyzing the problem, Jules provided a three-step coding solution. Once the user agreed, the model automatically generated code that could be merged directly into the existing GitHub project.
The Game Agent is the most interesting demo.
Google highlighted that Gemini 2.0 can understand Android screen sharing and user voice, performing the demo’s tasks without additional training.
In the demo, the user shared their phone screen while playing a game and communicated with the Agent via voice. The Game Agent provided the best strategy for the next steps in real time.
Google is working with games like Clash of Clans and Boom Beach to help the Agent understand game rules and provide the best strategies. This feature is quite groundbreaking, especially for strategy games—AI is rapidly advancing, and human understanding of strategy may soon be outmatched, or only the top minds might be able to compete with AI.
At the moment, Gemini 2.0 is not yet fully available to all users. Google is opening it up to developers and trusted testers, meaning we still have a while before these Agent features are widely accessible. Nonetheless, the demonstration is thrilling.
When Gemini 2.0 is fully launched, Google is likely to integrate these Agent features into Gemini and search functions first, rather than releasing them as standalone products.
Earlier this year, Google explored integrating AI into its search features. In October, Google announced that its AI-powered summary feature in search gained 1 billion monthly users. In the future, Google plans to use Gemini 2.0’s advanced reasoning capabilities to address more complex topics and multi-step queries, including advanced math, multimodal queries, and coding.
Additionally, beyond exploring virtual Agent capabilities, Google plans to apply Gemini 2.0’s spatial reasoning in robotics, aiming for Agents to assist in real-world scenarios.
2. Gemini Flash Regular Updates
So, what model will users actually be able to use immediately?
The answer is Gemini 2.0 Flash.
As a distilled smaller version of Google’s large model, Gemini 2.0 Flash (dialogue-optimized version) will become the default model for Google Gemini.

Google also introduced a new feature called "Deep Research," which leverages advanced reasoning and long-context capabilities to assist with research, enabling users to explore complex topics and compile reports, now available in Gemini’s premium version.
Gemini 2.0 Flash has noticeable improvements over the previous generation, essentially equating to the Pro version of the previous model.
As a part of the 2.0 family, Gemini 2.0 Flash also supports multimodal input, including images, video, and audio. It now supports multimodal output, such as generating mixed-image-and-text content, and can generate controllable multilingual text-to-speech (TTS) audio. It also natively integrates tools like Google Search, code execution, and user-defined functions.
3. Project Astra: A Model Prepared for Google Glass, with Infinite Memory?
Google also highlighted Project Astra, with the following improvements:
-
Smoother Conversations: Project Astra can now converse across multiple languages and mixed languages and better understand different accents and rare words.
-
New Tool Usage: With Gemini 2.0, Project Astra can use Google Search, Google Lens, and Google Maps to assist users in everyday tasks.
-
Stronger Memory: Project Astra’s memory has been enhanced, allowing it to remember conversations for up to 10 minutes, offering better personalized services.
-
Lower Latency: Thanks to new streaming technology and native audio understanding, the agent can understand language with near-human conversational delay.
Project Astra is Google’s forward-thinking project for its smart glasses.
Many companies, including Meta and Ray-Ban, have explored the potential of glasses as next-gen smart hardware.
One significant update is the memory capability. In an interview, DeepMind CEO Demis Hassabis mentioned that during the Gemini 1.5 era, internal testing had expanded its context window to over 10 million tokens. The model is now approaching infinite memory. However, longer memory comes at the cost of slower speeds. Demis Hassabis believes that in a short time, we’ll truly have infinite context length.
This is crucial for the assistant Google aims to build. Demis Hassabis describes the future world: "You use this assistant on your computer, then walk out the door, put on your glasses, or use your phone, and it’s always with you. It remembers your conversations and what you want to do, offering real personalization. We humans can’t remember everything, but AI will remember it all, providing inspiration and new plans."
4. The Age of Agents Has Arrived?
Since last year, people have pointed out that Agents are the future of AI development.
However, over the past year, the term "Agent" has been relatively quiet, sometimes being misused as a synonym for AI applications.
But at the end of this year, we are starting to see some promising progress.
First, Anthropic launched an Agent mode for computer use.
In China, Zhipu AI released a demo video of a mobile Agent performing tasks like operating WeChat.
Next year, OpenAI’s collaboration with Apple Intelligence remains unclear, but many expect it will offer many users their first experience with a simple Agent feature on mobile, enhancing productivity.
And now, we see Google releasing Agent demos for browsers and Android phones.
Agent technology still faces many challenges. People worry about potential security risks, privacy issues, and other dangers.
However, for ordinary users, Agent technology feels like the most "AI-like" innovation. Fully automated task completion, almost like magic, doesn’t require any technical background and can instantly enhance productivity and user experience.
The improvement of Agent capabilities also lays the foundation for the entry of new smart hardware into people’s lives—only when voice commands enable glasses to complete tasks automatically will many tasks shift from smartphones to new smart hardware terminals.
As Google AI Studio’s product manager Logan Kilpatrick said earlier today: the future is the era of Agents.