OpenAI's O3 system marks a significant leap in AI capabilities, achieving groundbreaking scores on ARC-AGI benchmarks. Explore the comprehensive evaluation report and its implications for the path toward Artificial General Intelligence (AGI).
OpenAI has released o3, a significant leap compared to o1, excelling in a range of benchmark tests in programming, mathematics, and science. It particularly achieved major breakthroughs in the ARC-AGI test. Does this mean humanity will witness the dawn of AGI by 2025? Here, we've compiled the evaluation report of o3, written by the founder of the ARC-AGI testing standards. The original title is "OpenAI o3 Breakthrough High Score on ARC-AGI-Pub."
Main Text:
OpenAI trained the new o3 system using the ARC-AGI-1 public training dataset, achieving a groundbreaking 75.7% score on our public leaderboard with a $10k compute cost limit on a semi-private evaluation dataset. A higher computation configuration (172 times the compute power) achieved 87.5%.

This marks a significant leap in AI capabilities, surprising many by demonstrating a novel task adaptability that previous GPT models did not possess. In contrast, the ARC-AGI-1 progressed from 0% with GPT-3 in 2020 to 5% with GPT-4o in 2024, over four years. For o3, all our intuitions about AI capabilities need to be reset.
The ARC Prize’s mission extends beyond being the first benchmark test: it is the North Star for AGI. We are excited to continue collaborating with the OpenAI team and other partners next year to design the next generation of sustainable AGI benchmark tests.
ARC-AGI-2 (same test format — easy for humans, harder for AI) will be released alongside the 2025 ARC Prize. We are committed to running the grand competition until an efficient open-source solution is created, with scores reaching 85%.
Below is the full test report.
OpenAI o3 ARC-AGI Test Results
We tested the o3 system on two sets of ARC-AGI datasets:
Semi-private Evaluation: 100 private tasks to assess overfitting
Public Evaluation: 400 public tasks
According to OpenAI’s instructions, we tested at two computational scales with different sampling sizes: 6 (high efficiency) and 1024 (low efficiency, 172x the compute).
Here are the test results:
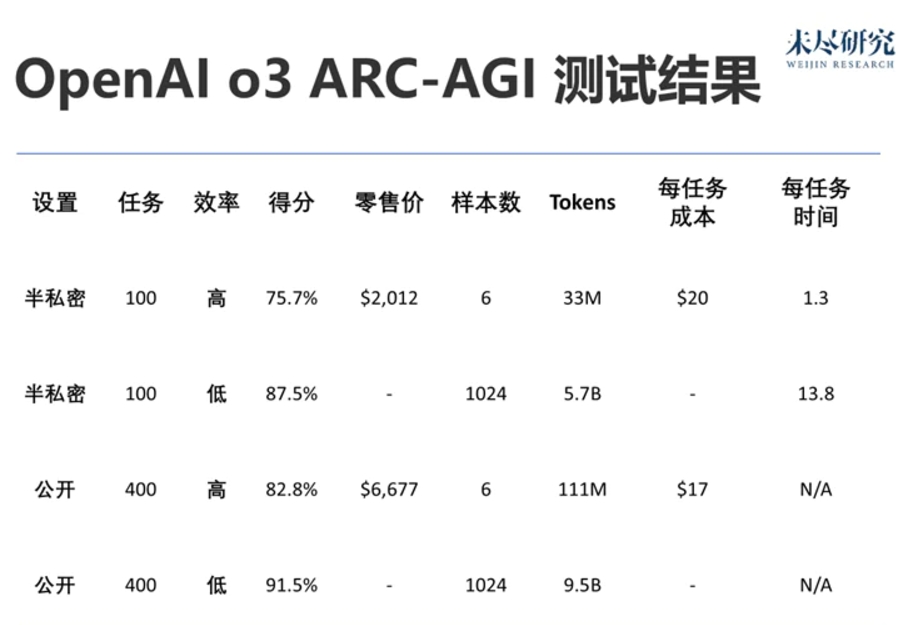
Due to the differences in inference budgets, efficiency (e.g., computational cost) is now a necessary metric when reporting performance. We recorded the total cost and the cost per task as preliminary measures of efficiency. The industry needs to collaborate on which metrics best reflect efficiency, but starting with cost is a good choice.
In the high-efficiency mode, a score of 75.7% met the ARC-AGI public evaluation budget rules (cost < $10k), securing the first place on the public leaderboard!
In low-efficiency mode, with a score of 87.5%, despite the high cost, performance increased with additional computational resources (at least up to this level).
Although the cost per task is significant, these results were not merely achieved through “brute-force computation.” OpenAI’s new o3 model has made a major leap in AI's ability to adapt to new tasks. This is not just incremental improvement, but a real breakthrough, marking a qualitative leap in AI capability compared to previous large language models. o3 is a system that can adapt to previously unseen tasks, approaching human-level performance in the ARC-AGI domain.
Of course, this generality comes at a high cost, and it is currently not economically feasible: it costs about $5 per task for humans to solve ARC-AGI tasks (yes, we tried), while energy consumption is only a few cents. o3 in low-compute mode costs $17–20 per task. However, cost-performance may significantly improve over the next few months to years, and we should expect these capabilities to compete with human labor in the near future.
The improvements in o3 over the GPT series prove the importance of architecture. Even with more computational resources invested in GPT-4, such results could not be achieved. Simply scaling up from 2019 to 2023, using the same architecture, training a larger version, and using more data, is no longer enough to drive further progress. Future breakthroughs will rely on entirely new ideas.
Is o3 AGI?
ARC-AGI is a key benchmark for detecting major breakthroughs in AI, particularly in generalization capabilities, which other benchmarks with lower demands cannot show. However, it is important to clarify that ARC-AGI is not the “acid test” for AGI, as we have reiterated several times this year. It is a research tool designed to focus on the most challenging unsolved problems in AI, and it has served this role well over the past five years.
Passing ARC-AGI does not equate to achieving AGI. In fact, I believe o3 is not yet AGI. o3 still fails at some very simple tasks, indicating a fundamental difference from human intelligence.
Furthermore, early data suggests that the upcoming ARC-AGI-2 benchmark will still be a major challenge for o3, with scores possibly dropping below 30% even in high-compute mode (while a smart human can score over 95% without training). This suggests we can still create challenging, unsaturated benchmarks without relying on expert domain knowledge. Only when tasks that are simple for ordinary humans but difficult for AI become completely impossible, will we know AGI has truly arrived.
How Does o3 Differ from Old Models?
Why does o3 score far higher than o1? Why does o1 score higher than GPT-4o? I believe these results provide valuable data points for AGI research.
My mental model of LLMs is that they are like a repository of vector programs. When a prompt is given, they extract the program mapped by the prompt and “execute” it based on the previous inputs. LLMs store and manipulate millions of useful small programs through passive exposure to human-generated content.
This "memory, extraction, and application" paradigm can reach corresponding skill levels on any task with adequate training data, but it cannot adapt to novelty or learn new skills on the fly (i.e., it lacks fluid intelligence). This is evident in the poor performance of LLMs on ARC-AGI benchmarks — GPT-3 scored 0, GPT-4 close to 0, GPT-4o at 5%. Even scaling these models to their limits could not bring ARC-AGI scores close to the 50% achievable with basic brute-force enumeration from a few years ago.
To adapt to novelty, two conditions are needed: first, knowledge — a set of reusable functions or programs, which LLMs already have enough of; second, the ability to recombine these functions into an entirely new program when facing new tasks — task modeling. This is program synthesis, a feature that LLMs have long lacked. The o-series models address this issue.
Currently, we can only speculate on the specific workings of o3. However, the core mechanism seems to be natural language program search and execution in the token space: during the testing phase, the model searches within the possible chains of thought (CoTs) that describe the steps needed to solve the task. This approach might resemble Monte Carlo tree search in AlphaZero style. In o3’s case, this search seems guided by some kind of evaluation model. Notably, Demis Hassabis hinted in a 2023 interview that DeepMind was researching this idea — this research path has been brewing for some time.
Thus, while single-generation LLMs perform poorly on new tasks, o3 overcomes this barrier by generating and executing its own programs, where the programs themselves (CoTs) become the product of knowledge recombination. Although this is not the only viable method of knowledge recombination during the testing phase (other methods include test-phase training or searching in the latent space), the new ARC-AGI data suggests it represents the current cutting-edge approach.
Essentially, o3 represents a form of deep learning-guided program search. The model searches the “program space” (in this case, natural language programs — chains of thought describing the steps to solve the current task), a process guided by deep learning priors (base LLMs). Solving an ARC-AGI task requires millions of tokens and thousands of dollars because this search process needs to explore many paths in the program space — including backtracking.
However, there are two important distinctions between what is happening here and my previous description of “deep learning-guided program search” as the best path to AGI. The key is that the programs generated by o3 are natural language instructions (executed by the LLM), not executable symbolic programs. This leads to two consequences:
These programs cannot directly interact with reality via direct execution and task evaluation — they can only be adaptively evaluated by another model. However, this evaluation may fail when operating outside the distribution due to the lack of direct task grounding.
The system cannot independently gain the ability to generate and evaluate these programs (unlike systems like AlphaZero that can master games through self-learning). Instead, it relies on human-generated CoT data annotated by experts.
It is still unclear what the specific limitations of this new system are and how much scalability it has. Further testing is needed to draw conclusions. Nevertheless, the current performance represents an extraordinary achievement, clearly demonstrating that intuitively guided program search during testing is a powerful paradigm for constructing AI systems that adapt to a variety of tasks.
What’s Next?
First, promoting the open-source replication of o3 via the ARC Prize competition in 2025 will be key to advancing the research community. A thorough analysis of o3’s strengths and limitations is needed to understand its scaling behavior, the nature of potential bottlenecks, and predict the abilities that future developments may unlock.
Furthermore, ARC-AGI-1 is now nearing saturation — aside from o3’s new score, in fact, a large ensemble of low-compute Kaggle solutions can already achieve 81% in private evaluation.
We plan to raise the bar with a new version, ARC-AGI-2, which has been in development since 2022, promising a reset of the current state-of-the-art. Our goal is to push the boundaries of AGI research with evaluations that are difficult, yet signal strong progress, highlighting AI’s current limitations.
Early tests of ARC-AGI-2 suggest that even for o3, this will be a very challenging benchmark. Of course, the goal of the ARC Prize is to generate an efficient open-source solution. We plan to release ARC-AGI-2 alongside the ARC Prize in 2025 (expected to launch at the end of Q1).
Looking ahead, the ARC Prize Foundation will continue to create new benchmark tests to focus researchers’ attention on the most challenging unsolved problems on the path to AGI. We’ve already started developing third-generation benchmarks that completely depart from the 2019 ARC-AGI format, incorporating exciting new ideas.